Regression with XGBoost
Contents
Regression with XGBoost#
After a brief review of supervised regression, you’ll apply XGBoost to the regression task of predicting house prices in Ames, Iowa. You’ll learn about the two kinds of base learners that XGboost can use as its weak learners, and review how to evaluate the quality of your regression models.
Regression review#
Which of these is a regression problem?#
Here are 4 potential machine learning problems you might encounter in the wild. Pick the one that is a clear example of a regression problem.
Objective (loss) functions and base learners#
Decision trees as base learners#
It’s now time to build an XGBoost model to predict house prices - not in
Boston, Massachusetts, as you saw in the video, but in Ames, Iowa! This
dataset of housing prices has been pre-loaded into a DataFrame called
df. If you explore it in the Shell, you’ll see that there
are a variety of features about the house and its location in the city.
In this exercise, your goal is to use trees as base learners. By
default, XGBoost uses trees as base learners, so you don’t have to
specify that you want to use trees here with
booster=“gbtree”.
xgboost has been imported as xgb and the
arrays for the features and the target are available in X
and y, respectively.
df into training and testing sets, holding out 20%
for testing. Use a random_state of 123.
XGBRegressor as xg_reg, using
a seed of 123. Specify an objective of
“reg:linear” and use 10 trees. Note: You don’t have to
specify booster=“gbtree” as this is the default.
xg_reg to the training data and predict the labels of
the test set. Save the predictions in a variable called
preds.
rmse using np.sqrt() and the
mean_squared_error() function from
sklearn.metrics, which has been pre-imported.
# edited/added
from sklearn.metrics import mean_squared_error
df = pd.read_csv("archive/Extreme-Gradient-Boosting-with-XGBoost/datasets/ames_housing_trimmed_processed.csv")
X = df.iloc[:,:-1]
y = df.iloc[:,-1]
# Create the training and test sets
X_train, X_test, y_train, y_test= train_test_split(X, y, test_size=0.2, random_state=123)
# Instantiate the XGBRegressor: xg_reg
xg_reg = xgb.XGBRegressor(objective="reg:linear", n_estimators=10, seed=123)
# Fit the regressor to the training set
xg_reg.fit(X_train, y_train)
# Predict the labels of the test set: preds
## [15:32:17] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
## XGBRegressor(n_estimators=10, seed=123)
preds = xg_reg.predict(X_test)
# Compute the rmse: rmse
rmse = np.sqrt(mean_squared_error(y_test, preds))
print("RMSE: %f" % (rmse))
## RMSE: 78847.401758
Well done! Next, you’ll train an XGBoost model using linear base learners and XGBoost’s learning API. Will it perform better or worse?
Linear base learners#
Now that you’ve used trees as base models in XGBoost, let’s use the
other kind of base model that can be used with XGBoost - a linear
learner. This model, although not as commonly used in XGBoost, allows
you to create a regularized linear regression using XGBoost’s powerful
learning API. However, because it’s uncommon, you have to use XGBoost’s
own non-scikit-learn compatible functions to build the model, such as
xgb.train().
In order to do this you must create the parameter dictionary that
describes the kind of booster you want to use (similarly to how
you
created the dictionary in Chapter 1 when you used
xgb.cv()). The key-value pair that defines the booster type
(base model) you need is “booster”:“gblinear”.
Once you’ve created the model, you can use the .train() and
.predict() methods of the model just like you’ve done in
the past.
Here, the data has already been split into training and testing sets, so
you can dive right into creating the DMatrix objects
required by the XGBoost learning API.
DMatrix objects - DM_train for the
training set (X_train and y_train), and
DM_test (X_test and y_test) for
the test set.
“booster”
type you will use (“gblinear”) as well as the
“objective” you will minimize (“reg:linear”).
xgb.train(). You have to specify
arguments for the following parameters: params,
dtrain, and num_boost_round. Use
5 boosting rounds.
xg_reg.predict(),
passing it DM_test. Assign to preds.
# Convert the training and testing sets into DMatrixes: DM_train, DM_test
DM_train = xgb.DMatrix(data=X_train, label=y_train)
DM_test = xgb.DMatrix(data=X_test, label=y_test)
# Create the parameter dictionary: params
params = {"booster":"gblinear", "objective":"reg:linear"}
# Train the model: xg_reg
xg_reg = xgb.train(params = params, dtrain=DM_train, num_boost_round=5)
# Predict the labels of the test set: preds
## [15:32:18] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
preds = xg_reg.predict(DM_test)
# Compute and print the RMSE
rmse = np.sqrt(mean_squared_error(y_test,preds))
print("RMSE: %f" % (rmse))
## RMSE: 44331.645061
Interesting - it looks like linear base learners performed better!
Evaluating model quality#
It’s now time to begin evaluating model quality.
Here, you will compare the RMSE and MAE of a cross-validated XGBoost
model on the Ames housing data. As in previous exercises, all necessary
modules have been pre-loaded and the data is available in the DataFrame
df.
5 boosting rounds and
“rmse” as the metric.
# Create the DMatrix: housing_dmatrix
housing_dmatrix = xgb.DMatrix(data=X,label=y)
# Create the parameter dictionary: params
params = {"objective":"reg:linear", "max_depth":4}
# Perform cross-validation: cv_results
cv_results = xgb.cv(dtrain=housing_dmatrix, params=params, nfold=4, num_boost_round=5, metrics="rmse", as_pandas=True, seed=123)
# Print cv_results
## [15:32:19] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
## [15:32:19] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
## [15:32:19] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
## [15:32:19] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
print(cv_results)
# Extract and print final round boosting round metric
## train-rmse-mean train-rmse-std test-rmse-mean test-rmse-std
## 0 141767.488281 429.449371 142980.464844 1193.806011
## 1 102832.562500 322.503447 104891.398438 1223.161012
## 2 75872.621094 266.493573 79478.947265 1601.341377
## 3 57245.657226 273.633063 62411.919922 2220.151162
## 4 44401.291992 316.426590 51348.276367 2963.378029
print((cv_results["test-rmse-mean"]).tail(1))
## 4 51348.276367
## Name: test-rmse-mean, dtype: float64
Now, adapt your code to compute the “mae” instead of the
“rmse”.
# Create the DMatrix: housing_dmatrix
housing_dmatrix = xgb.DMatrix(data=X,label=y)
# Create the parameter dictionary: params
params = {"objective":"reg:linear", "max_depth":4}
# Perform cross-validation: cv_results
cv_results = xgb.cv(dtrain=housing_dmatrix, params=params, nfold=4, num_boost_round=5, metrics="mae", as_pandas=True, seed=123)
# Print cv_results
## [15:32:21] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
## [15:32:21] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
## [15:32:21] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
## [15:32:21] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
print(cv_results)
# Extract and print final round boosting round metric
## train-mae-mean train-mae-std test-mae-mean test-mae-std
## 0 127343.595703 668.167771 127634.185547 2404.009753
## 1 89770.031250 456.980559 90122.505860 2107.916842
## 2 63580.782226 263.442189 64278.558594 1887.552548
## 3 45633.181640 151.849960 46819.175781 1459.821980
## 4 33587.097656 87.003217 35670.655274 1140.613227
print((cv_results["test-mae-mean"]).tail(1))
## 4 35670.655274
## Name: test-mae-mean, dtype: float64
Great work!
Regularization and base learners in XGBoost#
Using regularization in XGBoost#
Having seen an example of l1 regularization in the video, you’ll now
vary the l2 regularization penalty - also known as
“lambda” - and see its effect on overall model performance
on the Ames housing dataset.
DMatrix from X and y
as before.
“objective” of “reg:linear” and
“max_depth” of 3.
xgb.cv() inside of a for loop and
systematically vary the “lambda” value by passing in the
current l2 value (reg).
“test-rmse-mean” from the last boosting round
for each cross-validated xgboost model.
# Create the DMatrix: housing_dmatrix
housing_dmatrix = xgb.DMatrix(data=X, label=y)
reg_params = [1, 10, 100]
# Create the initial parameter dictionary for varying l2 strength: params
params = {"objective":"reg:linear","max_depth":3}
# Create an empty list for storing rmses as a function of l2 complexity
rmses_l2 = []
# Iterate over reg_params
for reg in reg_params:
# Update l2 strength
params["lambda"] = reg
# Pass this updated param dictionary into cv
cv_results_rmse = xgb.cv(dtrain=housing_dmatrix, params=params, nfold=2, num_boost_round=5, metrics="rmse", as_pandas=True, seed=123)
# Append best rmse (final round) to rmses_l2
rmses_l2.append(cv_results_rmse["test-rmse-mean"].tail(1).values[0])
# Look at best rmse per l2 param
## [15:32:23] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
## [15:32:23] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
## [15:32:23] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
## [15:32:23] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
## [15:32:23] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
## [15:32:23] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
print("Best rmse as a function of l2:")
## Best rmse as a function of l2:
print(pd.DataFrame(list(zip(reg_params, rmses_l2)), columns=["l2","rmse"]))
## l2 rmse
## 0 1 52275.355469
## 1 10 57746.060547
## 2 100 76624.617188
Nice work! It looks like as as the value of ‘lambda’
increases, so does the RMSE.
Visualizing individual XGBoost trees#
Now that you’ve used XGBoost to both build and evaluate regression as well as classification models, you should get a handle on how to visually explore your models. Here, you will visualize individual trees from the fully boosted model that XGBoost creates using the entire housing dataset.
XGBoost has a plot_tree() function that makes this type of
visualization easy. Once you train a model using the XGBoost learning
API, you can pass it to the plot_tree() function along with
the number of trees you want to plot using the num_trees
argument.
“objective” of
“reg:linear” and a “max_depth” of
2.
10 boosting rounds and the parameter
dictionary you created. Save the result in xg_reg.
xgb.plot_tree(). It takes in two
arguments - the model (in this case, xg_reg), and
num_trees, which is 0-indexed. So to plot the first tree,
specify num_trees=0.
rankdir=“LR”.
# edited/added
import graphviz
import matplotlib.pyplot as plt
# Create the DMatrix: housing_dmatrix
housing_dmatrix = xgb.DMatrix(data=X, label=y)
# Create the parameter dictionary: params
params = {"objective":"reg:linear", "max_depth":2}
# Train the model: xg_reg
xg_reg = xgb.train(params=params, dtrain=housing_dmatrix, num_boost_round=10)
# Plot the first tree
## [15:32:25] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
xgb.plot_tree(xg_reg, num_trees=0)
plt.show()
# Plot the fifth tree
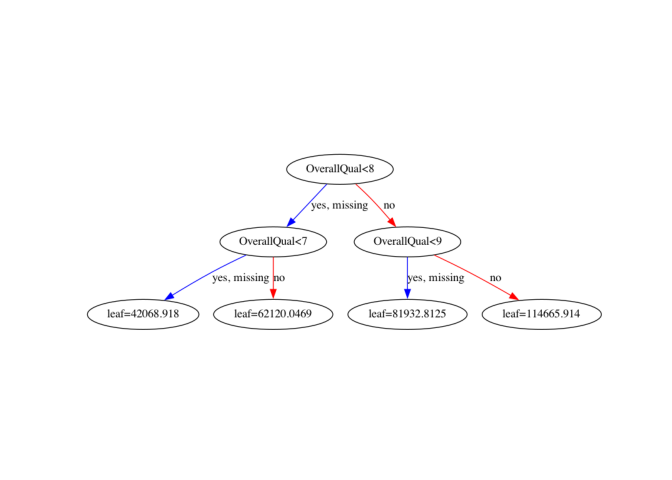
xgb.plot_tree(xg_reg, num_trees=4)
plt.show()
# Plot the last tree sideways
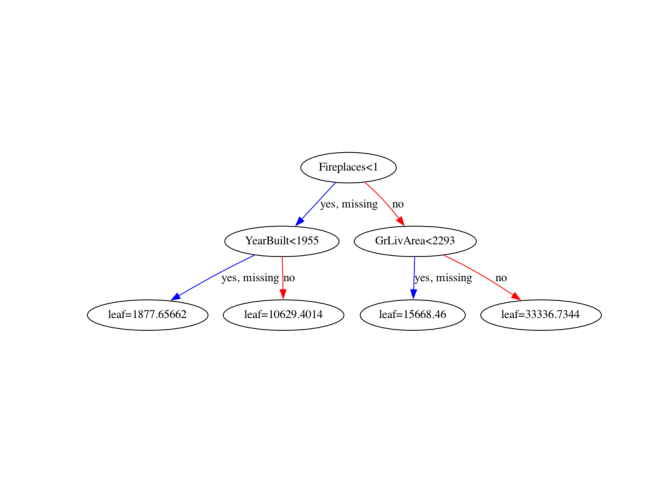
xgb.plot_tree(xg_reg, num_trees=9, rankdir='LR')
plt.show()
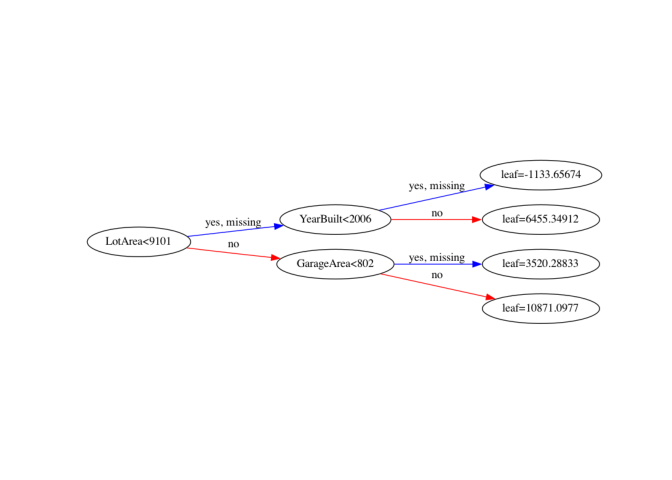
Excellent! Have a look at each of the plots. They provide insight into how the model arrived at its final decisions and what splits it made to arrive at those decisions. This allows us to identify which features are the most important in determining house price. In the next exercise, you’ll learn another way of visualizing feature importances.
Visualizing feature importances: What features are most important in my dataset#
Another way to visualize your XGBoost models is to examine the importance of each feature column in the original dataset within the model.
One simple way of doing this involves counting the number of times each
feature is split on across all boosting rounds (trees) in the model, and
then visualizing the result as a bar graph, with the features ordered
according to how many times they appear. XGBoost has a
plot_importance() function that allows you to do exactly
this, and you’ll get a chance to use it in this exercise!
DMatrix from X and y
as before.
“objective”
(“reg:linear”) and a “max_depth” of
4.
10 boosting rounds, exactly as you did
in the previous exercise.
xgb.plot_importance() and pass in the trained model to
generate the graph of feature importances.
# edited/added
import matplotlib.pyplot as plt
# Create the DMatrix: housing_dmatrix
housing_dmatrix = xgb.DMatrix(data=X, label=y)
# Create the parameter dictionary: params
params = {"objective":"reg:linear", "max_depth":4}
# Train the model: xg_reg
xg_reg = xgb.train(params=params, dtrain=housing_dmatrix, num_boost_round=10)
# Plot the feature importances
## [15:32:29] WARNING: src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
xgb.plot_importance(xg_reg)
plt.show()
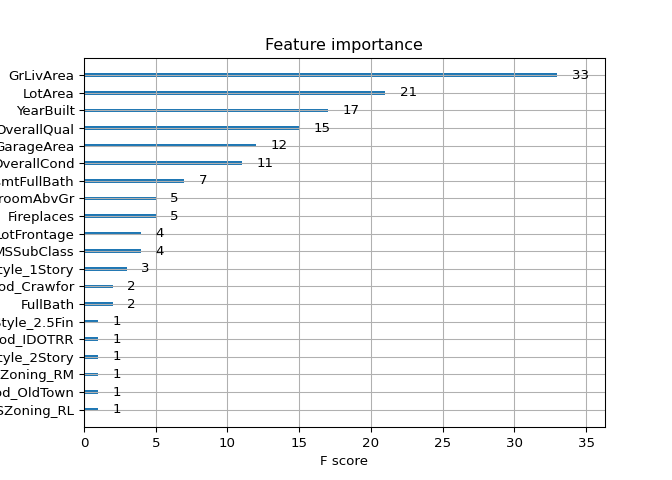
Brilliant! It looks like GrLivArea is the most important
feature. Congratulations on completing Chapter 2!