Discovering interpretable features
Contents
Discovering interpretable features#
In this chapter, you’ll learn about a dimension reduction technique called “Non-negative matrix factorization” (“NMF”) that expresses samples as combinations of interpretable parts. For example, it expresses documents as combinations of topics, and images in terms of commonly occurring visual patterns. You’ll also learn to use NMF to build recommender systems that can find you similar articles to read, or musical artists that match your listening history!
Non-negative matrix factorization (NMF)#
Non-negative data#
Which of the following 2-dimensional arrays are examples of non-negative data?
- A tf-idf word-frequency array.
- An array daily stock market price movements (up and down), where each row represents a company.
- An array where rows are customers, columns are products and entries are 0 or 1, indicating whether a customer has purchased a product.
1 only
2 and 3
1 and 3
NMF applied to Wikipedia articles#
In the video, you saw NMF applied to transform a toy word-frequency
array. Now it’s your turn to apply NMF, this time using the tf-idf
word-frequency array of Wikipedia articles, given as a csr matrix
articles. Here, fit the model and transform the articles.
In the next exercise, you’ll explore the result.
NMF from sklearn.decomposition.
NMF instance called model with
6 components.
articles.
.transform() method of model to
transform articles, and assign the result to
nmf_features.
nmf_features to get a first idea what it looks like
(.round(2) rounds the entries to 2 decimal places.)
# Import NMF
from sklearn.decomposition import NMF
# Create an NMF instance: model
model = NMF(n_components=6)
# Fit the model to articles
model.fit(articles)
# Transform the articles: nmf_features
## NMF(n_components=6)
nmf_features = model.transform(articles)
# Print the NMF features
print(nmf_features.round(2))
## [[0. 0. 0. 0. 0. 0.44]
## [0. 0. 0. 0. 0. 0.57]
## [0. 0. 0. 0. 0. 0.4 ]
## [0. 0. 0. 0. 0. 0.38]
## [0. 0. 0. 0. 0. 0.49]
## [0.01 0.01 0.01 0.03 0. 0.33]
## [0. 0. 0.02 0. 0.01 0.36]
## [0. 0. 0. 0. 0. 0.49]
## [0.02 0.01 0. 0.02 0.03 0.48]
## [0.01 0.03 0.03 0.07 0.02 0.34]
## [0. 0. 0.53 0. 0.03 0. ]
## [0. 0. 0.36 0. 0. 0. ]
## [0.01 0.01 0.31 0.06 0.01 0.02]
## [0. 0.01 0.34 0.01 0. 0. ]
## [0. 0. 0.43 0. 0.04 0. ]
## [0. 0. 0.48 0. 0. 0. ]
## [0.01 0.02 0.38 0.03 0. 0.01]
## [0. 0. 0.48 0. 0. 0. ]
## [0. 0.01 0.55 0. 0. 0. ]
## [0. 0. 0.47 0. 0. 0. ]
## [0. 0.01 0.02 0.52 0.06 0.01]
## [0. 0. 0. 0.51 0. 0. ]
## [0. 0.01 0. 0.42 0. 0. ]
## [0. 0. 0. 0.44 0. 0. ]
## [0. 0. 0. 0.5 0. 0. ]
## [0.1 0.09 0. 0.38 0. 0.01]
## [0. 0. 0. 0.57 0. 0.01]
## [0.01 0.01 0. 0.47 0. 0.01]
## [0. 0. 0. 0.58 0. 0. ]
## [0. 0. 0. 0.53 0.01 0.01]
## [0. 0.41 0. 0. 0. 0. ]
## [0. 0.61 0. 0.01 0. 0. ]
## [0.01 0.27 0. 0.02 0.01 0. ]
## [0. 0.64 0. 0. 0. 0. ]
## [0. 0.61 0. 0. 0. 0. ]
## [0. 0.34 0. 0. 0. 0. ]
## [0.01 0.32 0.02 0. 0.01 0. ]
## [0.01 0.21 0.01 0.05 0.02 0.01]
## [0.01 0.47 0. 0.02 0. 0. ]
## [0. 0.64 0. 0. 0. 0. ]
## [0. 0. 0. 0. 0.48 0. ]
## [0. 0. 0. 0. 0.49 0. ]
## [0. 0. 0. 0. 0.38 0.01]
## [0. 0. 0. 0.01 0.54 0. ]
## [0. 0. 0.01 0. 0.42 0. ]
## [0. 0. 0. 0. 0.51 0. ]
## [0. 0. 0. 0. 0.37 0. ]
## [0. 0. 0.04 0. 0.23 0. ]
## [0.01 0. 0.02 0.01 0.33 0.04]
## [0. 0. 0. 0. 0.42 0. ]
## [0.31 0. 0. 0. 0. 0. ]
## [0.37 0. 0. 0. 0. 0. ]
## [0.4 0.03 0. 0.02 0. 0.02]
## [0.38 0. 0. 0.04 0. 0.01]
## [0.44 0. 0. 0. 0. 0. ]
## [0.46 0. 0. 0. 0. 0. ]
## [0.28 0. 0. 0.05 0. 0.02]
## [0.45 0. 0. 0. 0.01 0. ]
## [0.29 0.01 0.01 0.01 0.19 0.01]
## [0.38 0.01 0. 0.1 0.01 0. ]]
Fantastic - let’s explore the meaning of these features in the next exercise!
NMF features of the Wikipedia articles#
Now you will explore the NMF features you created in the previous
exercise. A solution to the previous exercise has been pre-loaded, so
the array nmf_features is available. Also available is a
list titles giving the title of each Wikipedia article.
When investigating the features, notice that for both actors, the NMF feature 3 has by far the highest value. This means that both articles are reconstructed using mainly the 3rd NMF component. In the next video, you’ll see why: NMF components represent topics (for instance, acting!).
pandas as pd.
df from nmf_features using
pd.DataFrame(). Set the index to titles using
index=titles.
.loc\[\] accessor of df to select the
row with title ‘Anne Hathaway’, and print the result. These
are the NMF features for the article about the actress Anne Hathaway.
‘Denzel Washington’ (another
actor).
# Import pandas
import pandas as pd
# Create a pandas DataFrame: df
df = pd.DataFrame(nmf_features, index=titles)
# Print the row for 'Anne Hathaway'
print(df.loc['Anne Hathaway'])
# Print the row for 'Denzel Washington'
## 0 0.003845
## 1 0.000000
## 2 0.000000
## 3 0.575667
## 4 0.000000
## 5 0.000000
## Name: Anne Hathaway, dtype: float64
print(df.loc['Denzel Washington'])
## 0 0.000000
## 1 0.005601
## 2 0.000000
## 3 0.422348
## 4 0.000000
## 5 0.000000
## Name: Denzel Washington, dtype: float64
Great work! Notice that for both actors, the NMF feature 3 has by far the highest value. This means that both articles are reconstructed using mainly the 3rd NMF component. In the next video, you’ll see why: NMF components represent topics (for instance, acting!).
NMF reconstructs samples#
In this exercise, you’ll check your understanding of how NMF
reconstructs samples from its components using the NMF feature values.
On the right are the components of an NMF model. If the NMF feature
values of a sample are \[2, 1\], then which of the
following is most likely to represent the original sample? A
pen and paper will help here! You have to apply the same technique Ben
used in the video to reconstruct the sample \[0.1203 0.1764 0.3195
0.141\].
# edited/added
sample_feature = np.array([2, 1])
components = np.array([[1. , 0.5, 0. ],
[0.2, 0.1, 2.1]])
np.matmul(sample_feature.T, components)
## array([2.2, 1.1, 2.1])
[2.2, 1.1, 2.1][0.5, 1.6, 3.1][-4.0, 1.0, -2.0]
Well done, you’ve got it!
NMF learns interpretable parts#
NMF learns topics of documents#
In the video, you learned when NMF is applied to documents, the components correspond to topics of documents, and the NMF features reconstruct the documents from the topics. Verify this for yourself for the NMF model that you built earlier using the Wikipedia articles. Previously, you saw that the 3rd NMF feature value was high for the articles about actors Anne Hathaway and Denzel Washington. In this exercise, identify the topic of the corresponding NMF component.
The NMF model you built earlier is available as model,
while words is a list of the words that label the columns
of the word-frequency array.
After you are done, take a moment to recognize the topic that the articles about Anne Hathaway and Denzel Washington have in common!
pandas as pd.
components_df from
model.components\_, setting columns=words so
that columns are labeled by the words.
components_df.shape to check the dimensions of the
DataFrame.
.iloc\[\] accessor on the DataFrame
components_df to select row 3. Assign the
result to component.
.nlargest() method of component, and
print the result. This gives the five words with the highest values for
that component.
# edited/added
words = []
with open('archive/Unsupervised-Learning-in-Python/datasets/wikipedia-vocabulary-utf8.txt') as f:
words = f.read().splitlines()
# Import pandas
import pandas as pd
# Create a DataFrame: components_df
components_df = pd.DataFrame(model.components_, columns=words)
# Print the shape of the DataFrame
print(components_df.shape)
# Select row 3: component
## (6, 13125)
component = components_df.iloc[3]
# Print result of nlargest
print(component.nlargest())
## film 0.627924
## award 0.253151
## starred 0.245303
## role 0.211467
## actress 0.186412
## Name: 3, dtype: float64
Great work! Take a moment to recognise the topics that the articles about Anne Hathaway and Denzel Washington have in common!
Explore the LED digits dataset#
In the following exercises, you’ll use NMF to decompose grayscale images
into their commonly occurring patterns. Firstly, explore the image
dataset and see how it is encoded as an array. You are given 100 images
as a 2D array samples, where each row represents a single
13x8 image. The images in your dataset are pictures of a LED digital
display.
matplotlib.pyplot as plt.
0 of samples and assign the result
to digit. For example, to select column 2 of
an array a, you could use a\[:,2\]. Remember
that since samples is a NumPy array, you can’t use the
.loc\[\] or iloc\[\] accessors to select
specific rows or columns.
digit. This has been done for you. Notice that it is
a 1D array of 0s and 1s.
.reshape() method of digit to get a 2D
array with shape (13, 8). Assign the result to
bitmap.
bitmap, and notice that the 1s show the digit 7!
plt.imshow() function to display
bitmap as an image.
# edited/added
df = pd.read_csv('archive/Unsupervised-Learning-in-Python/datasets/lcd-digits.csv', header=None)
samples = df.values
digit = samples[0]
# Import pyplot
from matplotlib import pyplot as plt
# Select the 0th row: digit
digit = samples[0,:]
# Print digit
print(digit)
# Reshape digit to a 13x8 array: bitmap
## [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0.
## 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 1. 0.
## 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 1. 0.
## 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.
## 0. 0. 0. 0. 0. 0. 0. 0.]
bitmap = digit.reshape((13, 8))
# Print bitmap
print(bitmap)
# Use plt.imshow to display bitmap
## [[0. 0. 0. 0. 0. 0. 0. 0.]
## [0. 0. 1. 1. 1. 1. 0. 0.]
## [0. 0. 0. 0. 0. 0. 1. 0.]
## [0. 0. 0. 0. 0. 0. 1. 0.]
## [0. 0. 0. 0. 0. 0. 1. 0.]
## [0. 0. 0. 0. 0. 0. 1. 0.]
## [0. 0. 0. 0. 0. 0. 0. 0.]
## [0. 0. 0. 0. 0. 0. 1. 0.]
## [0. 0. 0. 0. 0. 0. 1. 0.]
## [0. 0. 0. 0. 0. 0. 1. 0.]
## [0. 0. 0. 0. 0. 0. 1. 0.]
## [0. 0. 0. 0. 0. 0. 0. 0.]
## [0. 0. 0. 0. 0. 0. 0. 0.]]
plt.imshow(bitmap, cmap='gray', interpolation='nearest')
plt.colorbar()
## <matplotlib.colorbar.Colorbar object at 0x7ffcdaca82e0>
plt.show()
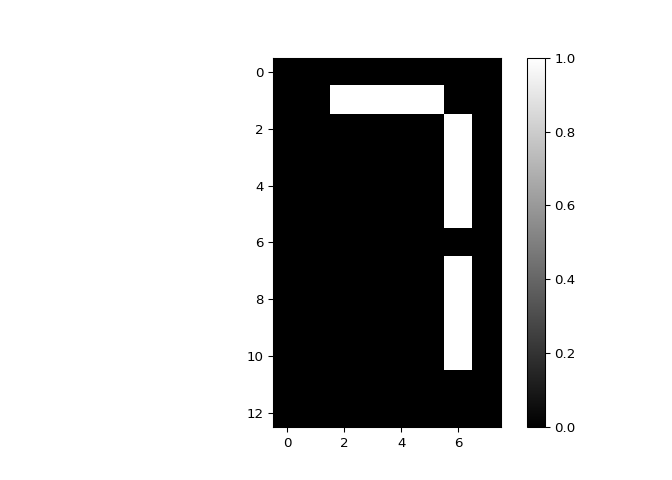
Excellent job! You’ll explore this dataset further in the next exercise and see for yourself how NMF can learn the parts of images.
NMF learns the parts of images#
Now use what you’ve learned about NMF to decompose the digits dataset.
You are again given the digit images as a 2D array samples.
This time, you are also provided with a function
show_as_image() that displays the image encoded by any 1D
array:
def show_as_image(sample):
bitmap = sample.reshape((13, 8))
plt.figure()
plt.imshow(bitmap, cmap='gray', interpolation='nearest')
plt.colorbar()
plt.show()
After you are done, take a moment to look through the plots and notice how NMF has expressed the digit as a sum of the components!
NMF from sklearn.decomposition.
NMF instance called model with
7 components. (7 is the number of cells in an LED display).
.fit_transform() method of model to
samples. Assign the result to features.
model.components\_), apply the show_as_image()
function to that component inside the loop.
0 of features to
digit_features.
digit_features.
# edited/added
def show_as_image(sample):
bitmap = sample.reshape((13, 8))
plt.figure()
plt.imshow(bitmap, cmap='gray', interpolation='nearest')
plt.colorbar()
# Import NMF
from sklearn.decomposition import NMF
# Create an NMF model: model
model = NMF(n_components=7)
# Apply fit_transform to samples: features
features = model.fit_transform(samples)
# Call show_as_image on each component
for component in model.components_:
show_as_image(component)
# Select the 0th row of features: digit_features
digit_features = features[0,:]
# Print digit_features
print(digit_features)
## [4.76823559e-01 0.00000000e+00 0.00000000e+00 5.90605054e-01
## 4.81559442e-01 0.00000000e+00 7.37546142e-16]
Great work! Take a moment to look through the plots and notice how NMF has expressed the digit as a sum of the components!
PCA doesn’t learn parts#
Unlike NMF, PCA doesn’t learn the parts of things. Its
components do not correspond to topics (in the case of documents) or to
parts of images, when trained on images. Verify this for yourself by
inspecting the components of a PCA model fit to the dataset of LED digit
images from the previous exercise. The images are available as a 2D
array samples. Also available is a modified version of the
show_as_image() function which colors a pixel red if the
value is negative.
After submitting the answer, notice that the components of PCA do not represent meaningful parts of images of LED digits!
PCA from sklearn.decomposition.
PCA instance called model with
7 components.
.fit_transform() method of model to
samples. Assign the result to features.
model.components\_), apply the show_as_image()
function to that component inside the loop.
# Import PCA
from sklearn.decomposition import PCA
# Create a PCA instance: model
model = PCA(n_components=7)
# Apply fit_transform to samples: features
features = model.fit_transform(samples)
# Call show_as_image on each component
for component in model.components_:
show_as_image(component)
Great work! Notice that the components of PCA do not represent meaningful parts of images of LED digits!
Building recommender systems using NMF#
Which articles are similar to ‘Cristiano Ronaldo’?#
In the video, you learned how to use NMF features and the cosine
similarity to find similar articles. Apply this to your NMF model for
popular Wikipedia articles, by finding the articles most similar to the
article about the footballer Cristiano Ronaldo. The NMF features you
obtained earlier are available as nmf_features, while
titles is a list of the article titles.
normalize from sklearn.preprocessing.
normalize() function to
nmf_features. Store the result as
norm_features.
df from norm_features,
using titles as an index.
.loc\[\] accessor of df to select the
row of ‘Cristiano Ronaldo’. Assign the result to
article.
.dot() method of df to
article to calculate the cosine similarity of every row
with article.
.nlargest() method of
similarities to display the most similar articles. This has
been done for you, so hit ‘Submit Answer’ to see the result!
# Perform the necessary imports
import pandas as pd
from sklearn.preprocessing import normalize
# Normalize the NMF features: norm_features
norm_features = normalize(nmf_features)
# Create a DataFrame: df
df = pd.DataFrame(norm_features, index=titles)
# Select the row corresponding to 'Cristiano Ronaldo': article
article = df.loc['Cristiano Ronaldo']
# Compute the dot products: similarities
similarities = df.dot(article)
# Display those with the largest cosine similarity
print(similarities.nlargest())
## Cristiano Ronaldo 1.000000
## Franck Ribéry 0.999972
## Radamel Falcao 0.999942
## Zlatan Ibrahimović 0.999942
## France national football team 0.999923
## dtype: float64
Great work - although you may need to know a little about football (or soccer, depending on where you’re from!) to be able to evaluate for yourself the quality of the computed similarities!
Recommend musical artists part I#
In this exercise and the next, you’ll use what you’ve learned about NMF
to recommend popular music artists! You are given a sparse array
artists whose rows correspond to artists and whose columns
correspond to users. The entries give the number of times each artist
was listened to by each user.
In this exercise, build a pipeline and transform the array into
normalized NMF features. The first step in the pipeline,
MaxAbsScaler, transforms the data so that all users have
the same influence on the model, regardless of how many different
artists they’ve listened to. In the next exercise, you’ll use the
resulting normalized NMF features for recommendation!
NMF from sklearn.decomposition.
Normalizer and MaxAbsScaler from
sklearn.preprocessing.
make_pipeline from sklearn.pipeline.
MaxAbsScaler called
scaler.
NMF instance with 20 components
called nmf.
Normalizer called
normalizer.
pipeline that chains together
scaler, nmf, and normalizer.
.fit_transform() method of pipeline
to artists. Assign the result to
norm_features.
# edited/added
from scipy.sparse import coo_matrix
df = pd.read_csv('archive/Unsupervised-Learning-in-Python/datasets/scrobbler-small-sample.csv')
artists1 = df.sort_values(['artist_offset', 'user_offset'], ascending=[True, True])
row_ind = np.array(artists1['artist_offset'])
col_ind = np.array(artists1['user_offset'])
data1 = np.array(artists1['playcount'])
artists = coo_matrix((data1, (row_ind, col_ind)))
# Perform the necessary imports
from sklearn.decomposition import NMF
from sklearn.preprocessing import Normalizer, MaxAbsScaler
from sklearn.pipeline import make_pipeline
# Create a MaxAbsScaler: scaler
scaler = MaxAbsScaler()
# Create an NMF model: nmf
nmf = NMF(n_components=20)
# Create a Normalizer: normalizer
normalizer = Normalizer()
# Create a pipeline: pipeline
pipeline = make_pipeline(scaler, nmf, normalizer)
# Apply fit_transform to artists: norm_features
norm_features = pipeline.fit_transform(artists)
Excellent work - now that you’ve computed the normalized NMF features, you’ll use them in the next exercise to recommend musical artists!
Recommend musical artists part II#
Suppose you were a big fan of Bruce Springsteen - which other musical
artists might you like? Use your NMF features from the previous exercise
and the cosine similarity to find similar musical artists. A solution to
the previous exercise has been run, so norm_features is an
array containing the normalized NMF features as rows. The names of the
musical artists are available as the list artist_names.
pandas as pd.
df from norm_features,
using artist_names as an index.
.loc\[\] accessor of df to select the
row of ‘Bruce Springsteen’. Assign the result to
artist.
.dot() method of df to
artist to calculate the dot product of every row with
artist. Save the result as similarities.
.nlargest() method of
similarities to display the artists most similar to
‘Bruce Springsteen’.
# edited/added
df = pd.read_csv('archive/Unsupervised-Learning-in-Python/datasets/artists.csv', header=None)
artist_names = df.values.reshape(111).tolist()
# Import pandas
import pandas as pd
# Create a DataFrame: df
df = pd.DataFrame(norm_features, index=artist_names)
# Select row of 'Bruce Springsteen': artist
artist = df.loc['Bruce Springsteen']
# Compute cosine similarities: similarities
similarities = df.dot(artist)
# Display those with highest cosine similarity
print(similarities.nlargest())
## Bruce Springsteen 1.000000
## Neil Young 0.959757
## Leonard Cohen 0.917936
## Van Morrison 0.885436
## Bob Dylan 0.866791
## dtype: float64
Well done, and congratulations on reaching the end of the course!
Final thoughts#
Final thoughts#
Congratulations, you sure have come a long way! You’ve learned all about Unsupervised Learning, and applied the techniques to real-world datasets, and built your knowledge of Python along the way. In particular, you’ve become a whiz at using scikit-learn and scipy for unsupervised learning challenges. You have harnessed both clustering and dimension reduction techniques to tackle serious problems with real-world datasets, such as clustering Wikipedia documents by the words they contain, and recommending musical artists to consumers.
Congratulations!#
You are now equipped to face a whole range of new challenges. Congratulations, once again, and keep coding!